
LLM 프로젝트 쉽게 접근하기: 스케일 업
LLM 프로젝트 구축 관심 가지신 여러분 안녕하세요, 사이냅소프트입니다 🥰
생성형 AI (LLM) 서비스를 사내에 구축하려고 하다 보면 한단계씩 해결해야 할 과제가 있습니다.
이번 시간에는 가상의 프로젝트 구축 과정을 가볍게 따라가면서, 어떤 기술과 자원이 문제 해결에 필요한지 맥락을 알아봅니다.

LLM 프로젝트, 더 키우려면?
작은 프로젝트가 성공적으로 진행되었다면, 더 큰 스케일로 비슷한 일을 구현하는 건 동일한 문제가 될까요? 기본 틀은 같은데, 추가적인 과제들이 생깁니다.
아! 스케일을 더 키우고, 랭체인을 활용해서 실제로 GPT를 이용한 좋은 서비스가 하나 있습니다.
사이냅소프트에서 만들었고, GPT 스토어에서 무료로 이용가능합니다. 😎 관련된 게시글은 부동산 감정평가 AI 사례 뜯어보기 1를 참고하시면 좋겠습니다.
해당 부동산 감정평가 AI가 첫 예시보다 더 큰 스케일의 프로젝트라면, 더, 더 큰 프로젝트는 어떨까요?
부동산 감정평가 AI 서비스를 보면서 알 수 있는 스케일업에서 생기는 추가 과제는 보통 다음과 같습니다.
더 많은 자료와 더 정확한 답변의 필요, 더 많은 질문에 대한 더 많은 비용, 더 빠른 답변
- 더 많은 자료와 더 정확한 답변의 필요(대량의 데이터 처리와 질 좋은 데이터 구축): 큰 규모의 프로젝트는 더 많은 데이터를 필요로 합니다. 작은 규모에서는 pdf로 된 매뉴얼 몇 장으로 충분했던 데이터가 기업 공시 자료 사이에서 원하는 자료 찾기, 법률 판례 찾기가 된다면 수만장에서 수백만장의 문서를 기반으로 하는 프로젝트가 됩니다.
어 근데, 검색이 안되는 스캔 문서인데 어떻게 할까요?더불어 LLM은 학습 데이터에 의존하므로 데이터 품질과 정제 과정도 신중히 고려되어야 합니다. 아르바이트 업무 매뉴얼은 세 장이었고 중복되는 내용이나 모순되는 내용이 있는지 금방 확인할 수 있습니다. 하지만 공장에서 부품 설계문서에 대한 수백 쪽의 보고서라면? 기업의 통계 보고서와, 매년 갱신되는 법률 개정안에 대한 문서라면? 검토하지 않으면 부정확한 답변으로 기껏 구축한 AI 서비스의 품질이 저하될 수 있습니다.
- 더 많은 질문에 대한 더 많은 비용(대량의 트래픽 처리): 큰 규모의 프로젝트는 더 많은 컴퓨팅 자원과 저장 공간을 필요로 합니다. 오픈소스나 자체구축을 한다면 LLM은 모델 크기가 크기 때문에 메모리와 GPU 자원을 효율적으로 관리해야 합니다. 클라우드 서비스를 활용하거나 자체 서버를 확장해야 할 수 있습니다. API를 쓴다면 B2C 서비스일 경우 수익구조보다 훨씬 큰 비용을 감당해야 할 수도 있습니다.
- 더 빠른 답변: 사용자가 기다리는 동안 LLM이 적절한 답변을 생성하는 데 시간이 오래 걸리면 사용성이 저하될 수 있습니다.
해결하기 위해서 보통 이런 기술이나 자원이 필요합니다.
|
더 많은 자료, 더 정확한 답변: |
더 많은 질문, 더 많은 비용 |
더 빠른 답변 |
|
RAG 기술, 체계적인 데이터 관리: 문서 구조화 등 |
가벼운 모델에 대한 수요 sLLM, 메모리와 GPU TPU를 효율적으로 쓰는 것에 대한 프레임워크와 언어: JAX/FLAX 등 |
모델 경량화 방법론: 가지치기(Pruning), 양자화(Quantization), 모델 컴프레션(Compression) 등 |
일전에 모델 경량화는 속도만 아니라 가격과 연결 지어서도 설명 드린 적이 있습니다. (https://www.synapsoft.co.kr/blog/32231/)
모두 다룰 수 없으니 이번에는 체계적인 데이터 관리 관련해서 이야기해보겠습니다.
아까 말했듯이 기존의 데이터가 스캔부터 시작해서 일반문서일 때가 많아서도 문제고. 그 다음에 정보가 중복되어서 답변이 이상해질 때도 있고, 데이터가 너무 많으니 그 사이에서 찾는 것도 문제가 됩니다. 그래서 큰 프로젝트에서는 양질의 데이터 구축이 선행되어야 합니다.
디지털 문서로 된 데이터 구축하기
1단계, 디지털 문서 관리 및 선별:
다양한 형식의 디지털 문서(PDF, HWP, MS 오피스 등)를 체계적으로 관리하고, 중복되거나 불필요한 정보를 제거하여 양질의 데이터를 선별합니다. 스캔한 이미지나 PDF라면 AI-OCR도 필요합니다. (https://www.synapsoft.co.kr/ocr/)
2단계 문서 구조화:
선별된 문서를 AI가 학습하기 쉽게 청크 단위로 구분해야 합니다.
분할된 각각의 청크가 적당한 의미를 담고 있어야 벡터 DB에 임베딩 했을 때 검색 결과의 정확성과 관련도가 크게 향상될 수 있습니다. 간단하게 예시를 들어보겠습니다. 만약의 한 표의 내용을 엉망으로 읽어냈다면 데이터가 어떻게 될까요?
- 데이터가 누락됐을 때

문서 파일에서 text를 제대로 읽어내지 못한다면 청크를 할 수 없는 단위의 글자가 나오기도 합니다. 특수문자를 인식은 했는데, 무슨 문자인지 모르는 오류 등. 극단적인 예이지만, 문서가 스캔으로 되어있을 때 곡면 왜곡 보정이나 회전 보정을 하는 기능이 없는 OCR로 문서를 읽어내면 이렇게 나올 수있습니다. - 데이터의 읽기 순서를 잘못 파악했을 때

‘태깅작업 등 메모리와 GPU TPU를 효율적 (Quantization), 모델 컴프레션’ 을 한 줄로 읽으면서 문장의 의미가 파괴되었습니다. 표라는 구조나 문단의 구조는 문서 정보에서 텍스트 다음으로 중요한 정보인데요. 이렇게 된 문장 상태로 RAG를 구축했을 때는 LLM도 정확한 답변을 낼 수 없어집니다.
오류가 많으면 청크를 제대로 할 수 없다는 걸 아시겠죠.
pdf가 수십장일 때는 조금 어려운 표 속 데이터 여도 실수를 직접 수정하면 됩니다. 하지만 수천장에서 수만장의 문서는 이런 일을 할 때 사람이 문서 한 장씩 신경 쓸 수 없습니다.
프로젝트 스케일업을 할 때 청크 과제를 해결하기 위해 어떤 문서의 표가 표라는 것을 정확히 알고, 이게 제목이고 그 아래 있는 게 문장이고, 이 페이지는 두 문단이라는 걸 미리 알고 있으면 어떨까요? 제목, 문단, 표, 이미지 등의 의미 있는 데이터를 구조화된 형태로 변환해서 Markdown, XML처럼 임베딩에 쓸 수 있는 포맷으로 제공하는 기술이 그래서 필요합니다.
사이냅 도큐애널라이저가 그 일을 합니다 😊
사이냅 도큐애널라이저
사이냅 도큐애널라이저는 다양한 문서의 표, 이미지 등 시각적 정보와 복잡한 문서 구조 정보를 분석하여 Markdown 및 XML, JSON 형태의 데이터로 변환해주는 디지털 자산화 솔루션으로 RAG기술과 함께 LLM에 필수적으로 요구되는 솔루션입니다.

제목, 문단, 표, 이미지는 의미적 관계를 가지고 있습니다. 제목은 그 아래 모든 문장, 이미지 내용을 대표하는 상위의 개념입니다. 각각의 표와 차트, 이미지도 표제목, 차트제목, 이미지 제목과 관계가 있습니다.

도큐애널라이저는 그런 내용을 ‘제대로’추출해서 LLM에 활용할 수 있는 데이터 포맷 (XML, Markdown)으로 변환해주는 역할을 합니다.
제대로 추출을 못 하면요?
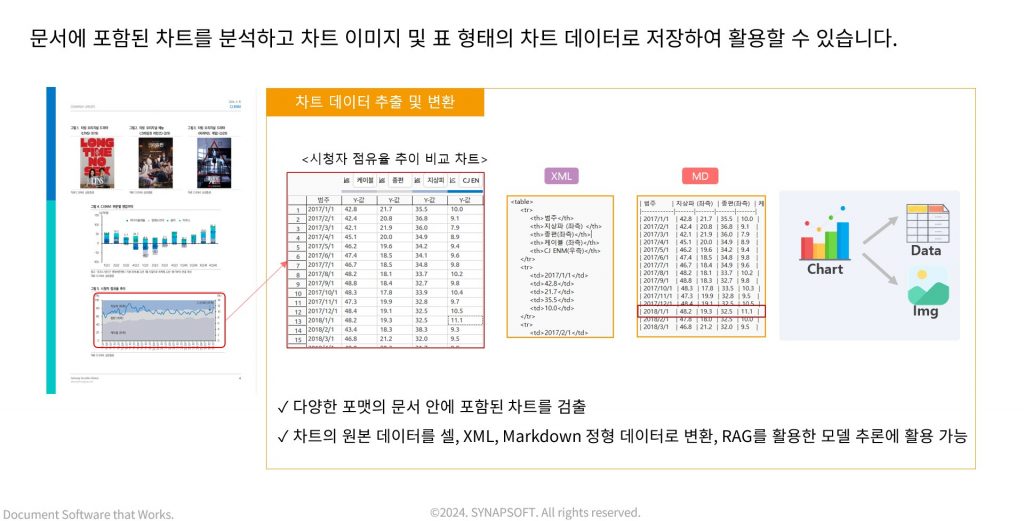
차트 전체를 생략하거나 이미지를 제대로 추출하지 않는 경우도 있는데, 그러면 이미지나 차트가 많은 문서는 구멍이 뚫린 상태의 문서가 됩니다. 활용도가 현저히 낮아지죠.
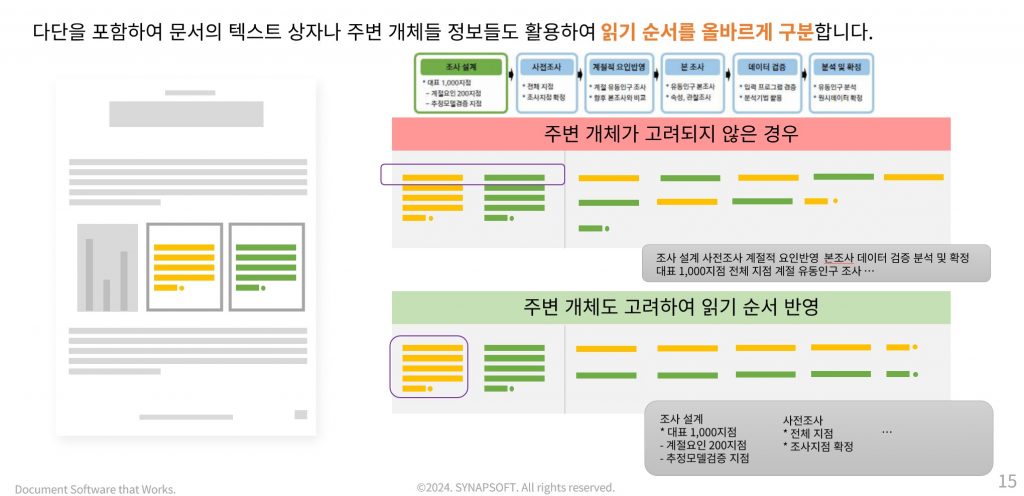
아까의 잘못된 청킹 사례 가 될 뻔했던 것도, 다단, 표 인식 주변 개체를 고려한 읽기 순서를 반영하는 기술로 해결할 수 있습니다.
사이냅 도큐애널라이저의 기능은 문서가 많은 큰 프로젝트를 할 때 반드시 필요한 솔루션입니다.
제품에 관한 상세내용은 사이냅 도큐애널라이저 페이지
(https://www.synapsoft.co.kr/docuanalyzer/ )에서 확인하실 수 있습니다.
+ 얼마나 많은 데이터가 사이냅 도큐애널라이저를 필요로 할까
IDC(인터내셔널 데이터 코퍼레이션)이라는 미국의 IT 및 통신, 컨수머 테크놀로지 부문 시장조사 및 컨설팅 기관이 있습니다. 여기에서 발간한 보고서는 2025년까지 전 세계 데이터의 용량이 175제타바이트를 넘을 것으로 전망합니다. 테라바이트, 페타바이트, 엑사바이트 다음이 제타바이트네요. 그리고 추산하기를 전체 기업 데이터의 80% 이상이 ‘비정형’ 형식으로 구성되어 있다고 합니다. 정확하지는 않지만 추산에 추산을 거듭할 수는 있을 것 같습니다.
이 비정형 데이터 중 많은 수가 ppt나 pdf, word, png 처럼 우리가 업무 할 때 쓰는 일반 문서라고 부르는 것들일 겁니다.
여기에는 태그나 메타데이터가 없어서 데이터의 의미나 계층을 컴퓨터 프로그램이 구분하고 일하기가 어렵죠. 실제로 사람이 문서를 열어서 읽으면 그 계층 구조를 이해할 수 있다고 해도요.
이 중 RAG 구축할 때 등 우리에게 필요한 문서를 XML, HTML, JSON처럼 반정형 데이터(데이터의 구조 정보를 데이터와 함께 제공하는 파일 형식의 데이터)로 만드는데 사이냅 도큐애널라이저가 쓰일 수 있습니다.
디지털 문서로 된 데이터 구축하기
이 이야기는 LLM 프로젝트의 스케일업을 하려다 보니, 큰 프로젝트에서 양질의 데이터 구축이 선행되어야 하기 때문에 많은 양의 문서 데이터를 구조화해서 청크 하던 중이었습니다.
마저 이야기하자면
3단계, 데이터 보안 및 개인정보 보호: 민감한 정보가 포함된 문서 데이터를 익명화하고 접근 권한을 관리하여 보안을 강화하는 단계가 필요합니다. 어떤 데이터는 사람마다 접근권한이 다를 수 있고, 자동으로 업데이트 되는 데이터 중에는 민감한 개인정보가 있을 수도 있습니다.
디지털 문서 자산화와 LLM학습데이터 구축:
빠르게 발전하는 sLLM에 대응하기 위해 디지털 문서를 자산화 시켜두면, 새로운 모델이 나와도 빠르게 적용할 수 있습니다.
정리
오늘은 스노우 볼처럼 작은 LLM 프로젝트를 만들 때 신경 쓰게 되는 부분에서부터, 눈덩이를 굴려 프로젝트를 스케일업 할 때의 과제를 알아보았습니다. 그리고 그에 필요한 기술 중 한 부분을 좀 더 자세히, 그러나 가벼운 수준에서 맥락 위주로 알아보았습니다.
작은 프로젝트를 할 때는 서비스의 기본적인 요소와 그 관계에 대해서 이해하게 된다면, 큰 프로젝트에서는 실제 기업이 마주치는 과제와 그를 해결하기 위한 기술에 대해서 맥락을 짚어가면서 알 수 있어 좋습니다.
다음번에는 또 다른 기술 소개로 돌아오겠습니다. 10월을 기다려 주세요!
더 읽어보기
오늘의 글이 재밌으셨다면 사이냅소프트에서 다음의 페이지들을 읽어보시면 좋을 것 같아요. 다음 편의 내용과도 관련있습니다.
AI 시장 현황, AI 기술 트렌드 by Alex 시리즈
1. 시장알기: 2024 생성형 AI 시장 브리핑: 리서치 중이라면 여기요🔍📈
2. 기술 알기: AI 기술, ‘비개발자’가 알아야 할 트렌드 1
3.기술 알기: AI 기술, ‘비개발자’가 알아야 할 트렌드 2
4. 자사 알기: 부동산 감정평가 AI 사례 뜯어보기 1
5. 자사 알기: 부동산 감정평가 AI 사례 뜯어보기 2

Alex는 누구인가요?
사이냅소프트의 마케터 Alex는 Designthinking FT 기업과 AI 교육 기업에서 일하며 기술 커뮤니케이션을 해왔습니다. Alex는 개발자가 비즈니스에 대해, 비개발자가 개발에 대해 쉽게 이해할 수 있는 컨텐츠를 만들고 상호 커뮤니케이션에서 시너지가 나도록 노력합니다.
지금은 TIL(Today I Learned): 깃헙 대신 블로그에서 잔디를 심는 🌱🌱🌱 중인데요, 사이냅소프트웨어나 위 내용이 더 궁금하시다면 mkt@synapsoft.co.kr로 연락주세요.

